Kalkulator Standar Deviasi
Ukur variabilitas dataset Anda secara presisi: hitung simpangan baku, varians, dan mean dalam satu langkah untuk kebutuhan riset, bisnis, dan sains.
Contoh Perhitungan
Mengapa Standar Deviasi adalah Kunci Analisis Data?
Standar deviasi (atau simpangan baku) adalah parameter statistik yang mengukur seberapa jauh titik-titik data menyebar dari nilai rata-ratanya. Angka rata-rata saja bisa menyesatkan: dua dataset bisa memiliki mean yang identik namun perilaku yang sama sekali berbeda. Dataset \{10, 10, 10, 10\} dan \{0, 5, 15, 20\} keduanya memiliki mean 10, tetapi standar deviasinya sangat berbeda karena variabilitas datanya berbeda drastis.
Di Indonesia, standar deviasi digunakan secara aktif di berbagai sektor profesional. BMKG menggunakannya untuk mengidentifikasi anomali cuaca dan variasi curah hujan di luar pola normal, yang menjadi dasar peringatan dini bencana. Di sektor keuangan, analis pasar modal menggunakan SD sebagai ukuran volatilitas harga saham atau komoditas. Di dunia akademik, SD adalah komponen wajib dalam laporan penelitian kuantitatif untuk menunjukkan sebaran data sampel. Nilai SD yang mendekati nol menandakan data sangat konsisten, sementara SD yang besar menandakan variasi atau risiko yang tinggi.
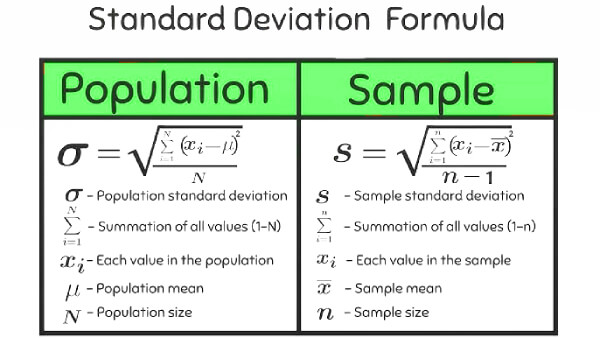
Standar Deviasi Populasi vs Sampel: Memilih Rumus yang Tepat
Memilih rumus yang tepat antara populasi dan sampel adalah keputusan metodologis yang menentukan validitas seluruh analisis statistik Anda. Kesalahan pada tahap ini bisa membuat laporan penelitian ditolak reviewer jurnal ilmiah.
Standar deviasi populasi \(\sigma\) digunakan ketika data yang Anda miliki mencakup seluruh anggota kelompok tanpa pengecualian, misalnya nilai ujian seluruh siswa di satu kelas atau data suhu harian satu bulan penuh dari satu stasiun cuaca: \[\sigma = \sqrt{\frac{\sum_{i=1}^{N}(x_i - \mu)^2}{N}}\] Standar deviasi sampel \(s\) digunakan ketika data Anda hanya mewakili sebagian dari populasi yang lebih besar, misalnya survei kepuasan 500 nasabah dari jutaan nasabah bank. Pembagi \(n-1\) (dikenal sebagai Koreksi Bessel) mengompensasi bias yang terjadi karena sampel cenderung meremehkan variabilitas populasi sebenarnya: \[s = \sqrt{\frac{\sum_{i=1}^{n}(x_i - \bar{x})^2}{n-1}}\] Panduan praktis: jika data Anda adalah hasil survei, eksperimen, atau pengambilan sampel acak, gunakan rumus sampel \(s\). Jika data mencakup seluruh populasi yang ingin Anda analisis, gunakan \(\sigma\).
Tips & Informasi 💡
- Masukkan Semua Titik Data: Menghilangkan satu data pun akan mengubah mean dan standar deviasi; pastikan dataset yang Anda masukkan lengkap sesuai sumber aslinya.
- Identifikasi Outlier Terlebih Dahulu: Data ekstrim yang jauh dari nilai wajar dapat menggelembungkan SD secara signifikan. Pertimbangkan untuk menganalisis dataset dengan dan tanpa outlier, lalu bandingkan hasilnya.
📋Langkah Menghitung
-
Masukkan semua titik data dataset Anda, dipisahkan dengan koma, pada kolom input yang tersedia.
-
Pilih jenis perhitungan: Populasi jika data mencakup seluruh kelompok, atau Sampel jika data hanya mewakili sebagian.
-
Klik "Hitung" untuk melihat hasil standar deviasi, varians, mean, nilai minimum, dan maksimum sekaligus.
Kesalahan yang Harus Dihindari ⚠️
- Salah Memilih Rumus Populasi atau Sampel: Menggunakan rumus populasi pada data survei (yang seharusnya menggunakan sampel) menghasilkan SD yang lebih kecil dari seharusnya dan melebih-lebihkan presisi data.
- Mengabaikan Outlier: Memasukkan data ekstrim tanpa pemeriksaan terlebih dahulu dapat meningkatkan SD secara dramatis dan membuat distribusi data tampak lebih tersebar dari kenyataan.
- Mengira Varians dan SD adalah Hal yang Sama: Varians adalah rata-rata dari kuadrat selisih data terhadap mean, sedangkan SD adalah akar kuadrat dari varians. Satuan varians adalah kuadrat dari satuan data asli, sehingga lebih sulit diinterpretasikan.
- Kesalahan Format Input: Tidak memisahkan angka dengan koma atau menggunakan spasi sebagai pemisah menyebabkan sistem membaca seluruh angka sebagai satu nilai tunggal.
Aplikasi Praktis Standar Deviasi📊
Kontrol Kualitas Produksi: Ukur konsistensi dimensi produk manufaktur; SD yang kecil menandakan proses produksi yang stabil dan terkontrol.
Analisis Risiko Keuangan: Hitung volatilitas return investasi atau fluktuasi harga komoditas sebagai dasar keputusan portofolio.
Validasi Data Penelitian: Sertakan nilai SD dalam laporan karya ilmiah untuk menunjukkan keandalan dan sebaran data sampel kepada reviewer jurnal.
Pertanyaan Seputar Layanan Kami
Apa perbedaan utama antara varians dan standar deviasi?
Kapan harus menggunakan rumus sampel dengan pembagi n-1?
Apa rumus lengkap standar deviasi populasi?
\[\sigma = \sqrt{\frac{\sum_{i=1}^{N}(x_i - \mu)^2}{N}}\]
di mana \(\mu\) adalah mean populasi, \(x_i\) adalah setiap titik data, dan \(N\) adalah jumlah total data dalam populasi. Proses perhitungannya: hitung mean, kurangi setiap data dengan mean, kuadratkan hasilnya, jumlahkan semua nilai kuadrat, bagi dengan N, lalu ambil akar kuadratnya.