Calculadora de Desviación Estándar
Calculadora de desviación estándar: dispersión, varianza y media para poblaciones y muestras
Ejemplos de cálculo
¿Cómo usar la calculadora de desviación estándar?
Introduce tu conjunto de datos separados por comas (por ejemplo: 10, 12, 23, 14). Selecciona si los datos representan una población completa o una muestra: la diferencia afecta directamente al denominador del cálculo y, por tanto, al resultado. Al pulsar "Calcular", obtendrás la desviación estándar, la media aritmética y la varianza, con el desglose paso a paso del procedimiento.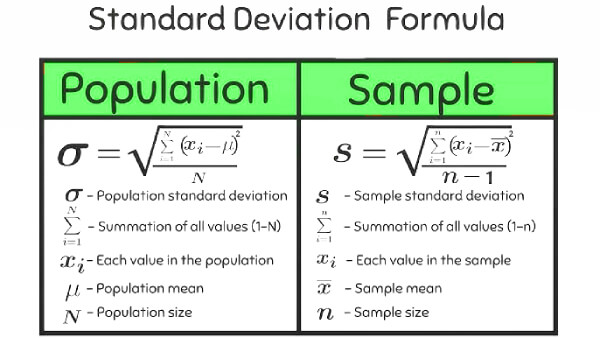
Aplicaciones de la desviación estándar en ciencia y finanzas
La desviación estándar es una de las métricas más versátiles del análisis cuantitativo. En control de calidad industrial, define los límites de tolerancia de un proceso: una pieza o producto que supere ±3 desviaciones estándar respecto a la media se considera fuera de especificación (principio Six Sigma). En meteorología, permite comparar la variabilidad climática entre regiones: una costa con temperaturas entre 18 °C y 28 °C (DE ≈ 2,5 °C) es mucho más predecible que un interior continental con temperaturas entre 0 °C y 40 °C (DE ≈ 10 °C) aunque ambas puedan tener medias similares. En finanzas, es la métrica estándar de volatilidad: un activo con retorno medio del 7% y DE del 10% es considerablemente menos arriesgado que otro con el mismo retorno pero DE del 50%, aunque este último también ofrezca mayor potencial de ganancia. En investigación científica y medicina, la desviación estándar acompaña a cualquier media reportada para indicar la dispersión de los datos y la fiabilidad del promedio.
Guía de Uso y Consejos 💡
- Usa el modo "Muestra" si tus datos son un subconjunto de un grupo mayor: el denominador N-1 (corrección de Bessel) produce un estimador estadísticamente insesgado.
- Verifica que el conjunto de datos no contenga letras, símbolos o espacios adicionales: un carácter no numérico puede invalidar el cálculo completo.
📋Pasos para Calcular
-
Escribe o pega tus datos numéricos separados por comas.
-
Selecciona el modo: "Muestra" (denominador N-1) o "Población" (denominador N).
-
Pulsa "Calcular" para obtener la desviación estándar, la varianza y la media.
Errores a evitar ⚠️
- Usar la fórmula de población (denominador N) cuando los datos son una muestra, lo que subestima la dispersión real de la población.
- Olvidar aplicar la raíz cuadrada al final: sin ese paso el resultado es la varianza, no la desviación estándar.
- Cometer un error en el cálculo de la media aritmética al inicio, lo que arrastra el error a todas las diferencias al cuadrado posteriores.
- No elevar al cuadrado las diferencias respecto a la media antes de sumarlas, lo que anularía los valores negativos y produciría un resultado de cero.
Aplicaciones prácticas📊
Control de calidad: verifica si la variabilidad de un proceso de producción está dentro de los límites de tolerancia especificados.
Finanzas e inversión: compara la volatilidad de distintos activos para evaluar el riesgo ajustado al retorno esperado.
Investigación y laboratorio: valida la precisión y repetibilidad de instrumentos de medición a partir de series de datos experimentales.